Architecture
Component diagram
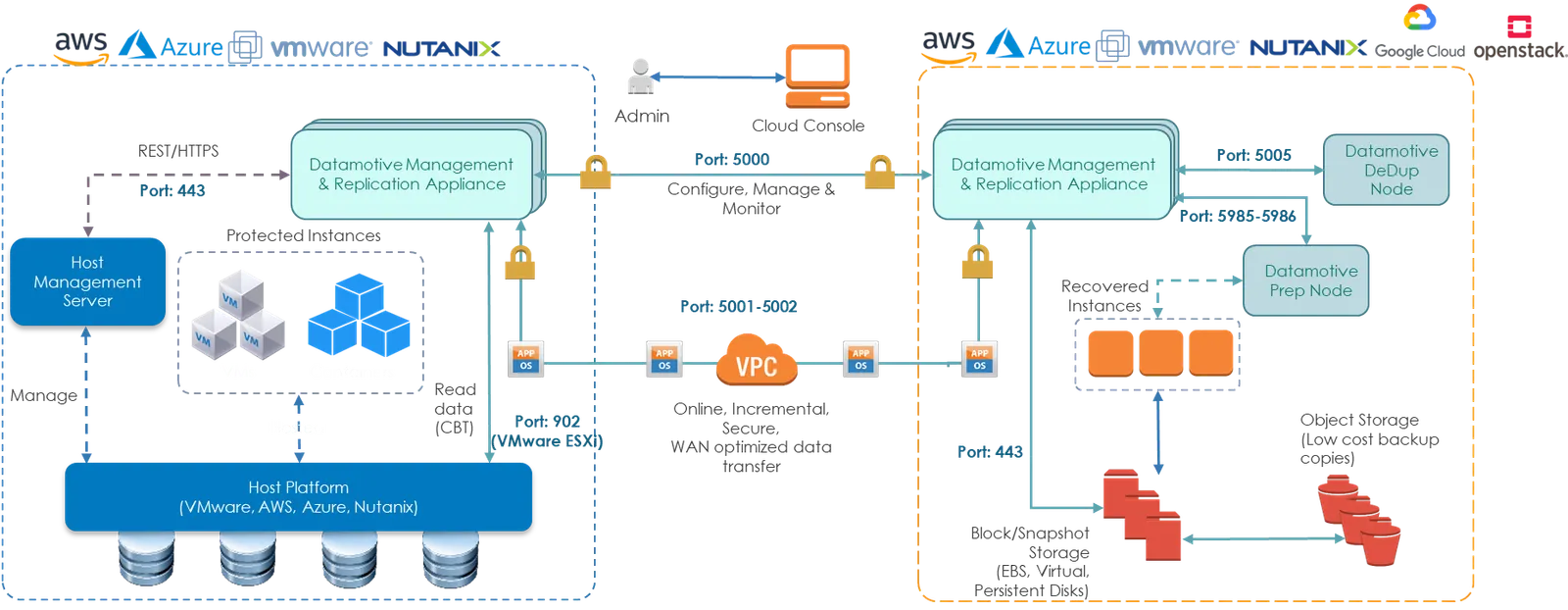
Detailed breakdown of Datamotive's management, replication, recovery preparation, and optimization components.
- Product
- Datamotive Platform
- Version
- v1.0
- Documentation status
- Published
- Last updated
- Updated
- Reading time
- 2 min read
Datamotive is composed of independently deployable components for management, replication, recovery preparation, and storage optimization. This modular design supports independent scaling, operational flexibility, fault isolation, cloud-native deployment models, and multi-site or multi-cloud deployments.
Appliance formats
All Datamotive appliances are based on hardened Ubuntu Server images except the Windows-based Prep Node. They are delivered as pre-packaged virtual appliances for hypervisor deployments or cloud-native images for public cloud deployments.
| Platform | Deployment format |
|---|---|
| VMware | OVA |
| Nutanix | OVA |
| AWS | Cloud-native AMI |
| Azure | Cloud-native VM image |
Control plane components
Management Server
The Datamotive Management Server is the central orchestration and control-plane component. It provides the UI, CLI, REST APIs, policy management, replication orchestration, recovery orchestration, scheduling, monitoring, alerting, reporting, inventory, metadata, and operational workflows.
The Management Server coordinates platform activities while maintaining metadata, workflow state, inventory information, and recovery orchestration logic.
API and console
The API layer handles authentication, authorization, request validation, and workflow routing. The console communicates through the API and exposes the plan builder, job monitor, recovery point browser, site and node inventory, and settings workflows.
Scheduler and job queue
The scheduler evaluates policy and plan schedules, then dispatches jobs through the queue. Nodes acknowledge work, stream progress, and return final job state.
Metadata store
The metadata store tracks plans, sites, nodes, recovery point indices, job records, user accounts, RBAC policies, and audit logs.
Data plane components
Replication Node
The Replication Node is responsible for block-level replication, incremental change processing, rolling-window transport, parallel stream handling, WAN-optimized data transfer, descriptor scheduling, validation, storage writes, recovery reads, flow control, and checkpoint finalization.
Replication Engine
The Replication Engine inside each node uses sliding-window parallel replication, target-side worker-driven flow control, descriptor-based scheduling, node-level backpressure, parallel chunk streaming, cloud-native storage integration, and horizontally scalable workers.
Recovery functions
Recovery functions coordinate disk reconstruction, snapshot finalization, Windows system checks, VM instantiation, network attachment, boot order, and recovery validation.
Recovery support components
Prep Node
The Prep Node is a Windows-based recovery preparation appliance in the recovery environment. It is used for Windows workload recovery, cross-platform migration, recovery preparation, boot remediation, and file system or registry compatibility checks.
DeDup Node
The DeDup Node is optional. It maintains chunk checksum indexes, previously transferred block metadata, deduplicated chunk references, and chunk reuse mappings. When enabled for suitable workloads, it reduces WAN bandwidth consumption, cross-cloud transfer cost, replication duration, and repetitive data transfer overhead.
Related docs
Was this page helpful?