Concepts
Replication engine
How Datamotive identifies changed blocks, schedules descriptors, streams chunks, applies backpressure, and finalizes recovery checkpoints.
- Product
- Datamotive Platform
- Version
- v1.0
- Documentation status
- Published
- Last updated
- Updated
- Reading time
- 2 min read
The Datamotive Replication Engine is a distributed, block-level replication framework for enterprise disaster recovery, migration, and workload portability. It is optimized for fragmented changed-block workloads, WAN-constrained links, cross-cloud data movement, cloud-native storage APIs, and high-churn environments.
Architectural objectives
The engine is designed to maintain predictable throughput across fragmented workloads, large parallel replication sets, WAN-based deployments, and high-latency cloud environments.
It improves WAN utilization by avoiding stop-and-wait transfer patterns. Instead of sending a batch and waiting for acknowledgement before sending the next batch, the engine keeps multiple chunks in flight.
Rolling-window replication model
The rolling-window model maintains continuous parallel replication streams. Each disk keeps independent replication state and a replication window, while the node maintains aggregate inflight limits to avoid memory amplification or storage overload.
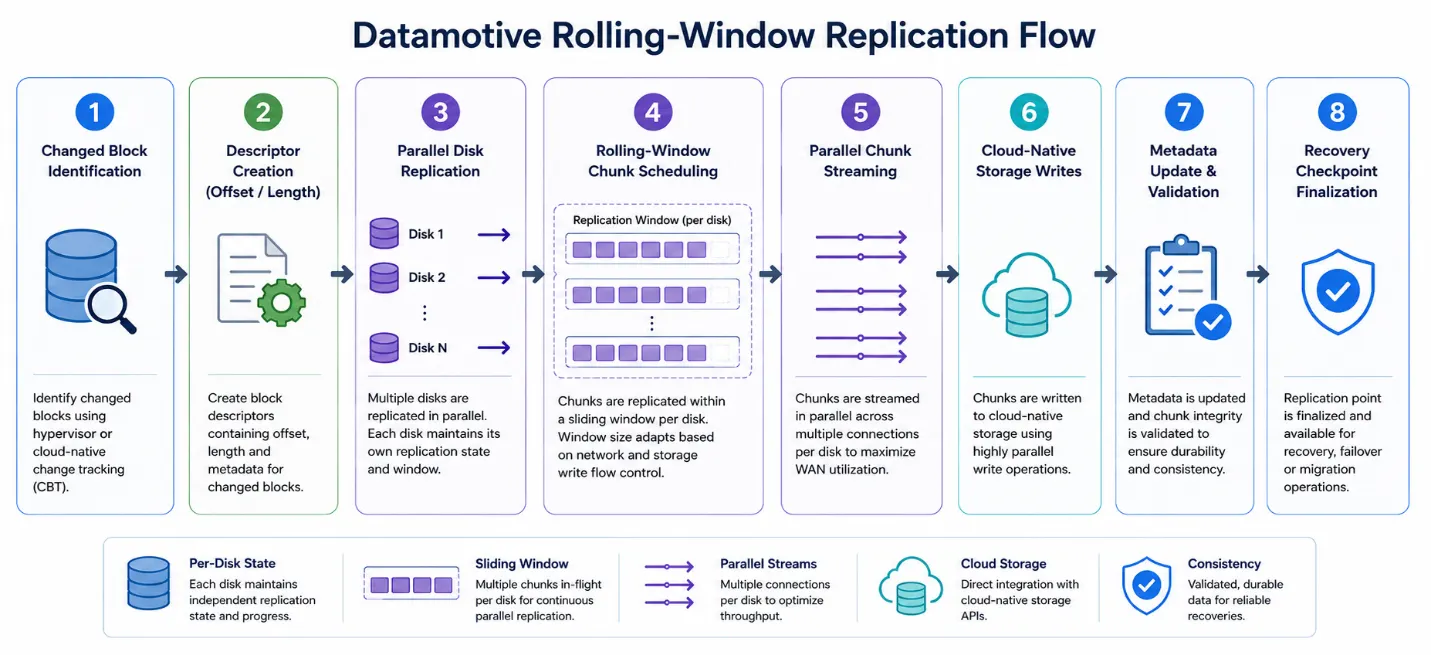
Replication flow
Identify changed blocks
The source adapter asks the hypervisor or cloud platform which blocks changed since the previous checkpoint. VMware uses CBT, Nutanix uses changed-region tracking, AWS uses incremental snapshot APIs, and Azure uses incremental snapshot page ranges.
Create descriptors
The engine creates descriptors containing offset, length, chunk metadata, and replication state. Descriptor-driven scheduling is optimized for fragmented workloads where changed blocks are not sequential.
Replicate disks in parallel
Multiple disks can progress independently. Each disk maintains its own replication state and window.
Schedule rolling-window chunks
The engine schedules chunks within a sliding window per disk. Window size adapts based on network conditions, cloud write behavior, and node pressure.
Stream chunks in parallel
Chunks are streamed across multiple connections and workers to reduce idle WAN periods, storage-write serialization, and pipeline starvation.
Write to cloud-native storage
Target workers write chunks to cloud-native or platform-native storage APIs, such as AWS EBS, Azure Managed Disks, VMware datastores, or Nutanix storage.
Validate metadata and chunks
The target validates chunk integrity, write completion, and metadata state before checkpoint publication.
Finalize the recovery checkpoint
The checkpoint becomes available for recovery, failover, test recovery, or migration operations.
Default operational parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| chunk_size | size | required | Default chunk size used by the replication engine. Default: 1 MB |
| per_disk_window | size | required | Default inflight window maintained per replicated disk. Default: 32 MB |
| intermediate_checkpoint_window | size | required | Amount of data between intermediate checkpoint operations. Default: 500 MB |
These defaults balance WAN efficiency, cloud write behavior, memory utilization, retransmission overhead, and fragmented CBT handling.
Worker-driven flow control
The replication engine uses a worker-controlled pull model:
- Workers request replication windows.
- Clients stream requested chunks.
- Workers control inflight concurrency.
- Replication pressure is centrally managed.
This improves replication fairness, backpressure management, cloud-write coordination, and large-scale stability.
Node-level backpressure
The engine maintains both per-disk replication windows and node-level inflight windows. Backpressure prevents excessive memory growth, cloud-write overload, uncontrolled bursts, and storage queue saturation.
Backpressure decisions consider cloud storage latency, write queue depth, chunk arrival behavior, replication-node pressure, errors, and retry behavior.
Adaptive window scaling
The engine dynamically adjusts replication window sizes based on storage-write pressure, WAN stability, cloud API responsiveness, retry rates, and concurrency.
Typical per-disk operational window levels are:
| Window level | Typical use |
|---|---|
| 16 MB | Constrained links, elevated write latency, or high retry rates. |
| 24 MB | Moderate pressure with stable but limited throughput. |
| 32 MB | Balanced default for common enterprise workloads. |
| 48 MB | Stable network and target write conditions. |
| 64 MB | High-capacity links and storage paths with low backpressure. |
Architectural advantages
| Area | Advantage |
|---|---|
| WAN efficiency | Reduced idle gaps, better bandwidth utilization, and lower sensitivity to round-trip time. |
| Fragmented workloads | Descriptor scheduling and sparse-write optimization handle non-sequential changed blocks efficiently. |
| Cloud integration | Parallel cloud writes and adaptive API usage improve target-side throughput. |
| Large-scale stability | Backpressure and adaptive concurrency keep node pressure controlled. |
| Horizontal scalability | Independent Replication Nodes distribute workloads and improve operational flexibility. |
Related docs
Was this page helpful?