Reference
Scale and performance guide
Architectural, scalability, sizing, performance, cloud quota, and operational guidance for Datamotive workload portability.
- Product
- Easy Hybrid DR
- Version
- v2.3.1
- Release status
- GA
- Documentation status
- Published
- Last updated
- Updated
- Reading time
- 17 min read
The Datamotive Workload Portability Platform is an enterprise-grade disaster recovery, workload mobility, and cross-cloud replication solution designed to provide scalable, predictable, and cloud-native protection for modern virtualized and cloud-hosted workloads.
Executive summary
The platform enables organizations to protect, migrate, and recover workloads across heterogeneous environments including VMware, Nutanix, Microsoft Azure and Amazon Web Services (AWS) using an agentless, block-level replication and cross-platform, cross-cloud recovery architecture optimized for enterprise environments.
Datamotive is designed to address the operational and scalability challenges associated with modern disaster recovery deployments, including:
- Large-scale parallel workload replication
- Highly fragmented block-change workloads
- WAN-constrained replication environments
- Cross-cloud recovery orchestration
- Recovery-time scalability
- Cost-efficient disaster recovery architectures
This guide provides detailed guidance for:
- Datamotive component architecture
- Replication engine scalability characteristics
- Management and replication node sizing
- Parallel replication and recovery limits
- Platform-specific scaling guidance
- Cloud API and quota considerations
The guidance in this document is intended for:
- Enterprise infrastructure architects
- Cloud architects
- Disaster recovery architects
- Cloud operations teams
- Managed service providers
- Datamotive deployment and support teams
Successful enterprise-scale disaster recovery deployments depend not only on replication throughput, but also on proper workload hygiene, network architecture, storage performance, and recovery orchestration design.
The Datamotive platform is designed to address these requirements through a scalable, cloud-native, horizontally extensible architecture capable of supporting enterprise-scale workload portability, migration, and disaster recovery initiatives across hybrid and multi-cloud environments.
Scope and assumptions
This document provides architectural, scalability, sizing, performance, and operational guidance for the Datamotive Workload Portability Platform across supported on-premises and public cloud environments.
Supported platforms
Datamotive supports replication, recovery, migration, and workload portability across the following infrastructure platforms.
| Supported source platform | Supported workloads |
|---|---|
| VMware vSphere | Virtual Machines |
| Nutanix AHV | Virtual Machines |
| Microsoft Azure | Azure Virtual Machines |
| Amazon Web Services (AWS) | EC2 Instances |
| Supported target platform | Recovery / replication target |
|---|---|
| VMware vSphere | Supported |
| Microsoft Azure | Supported |
| Amazon Web Services (AWS) | Supported |
| Nutanix AHV | Supported |
Supported use cases
The Datamotive platform is designed to support multiple workload portability and disaster recovery scenarios.
| Use case area | Scenarios |
|---|---|
| Disaster Recovery | On-premises to cloud DR; cloud to cloud DR; cross-region DR; multi-cloud DR; hybrid cloud DR. |
| Workload Mobility | Cross-cloud migration; data center evacuation; cloud onboarding; infrastructure modernization; workload rebalancing. |
| Enterprise Server Workloads | Application servers; database servers; file servers; web/application tiers; multi-tier enterprise applications. |
Architectural assumptions
The scalability and performance guidance in this document assumes the following baseline conditions.
| Area | Assumptions |
|---|---|
| Infrastructure assumptions | Enterprise-grade networking infrastructure; stable WAN connectivity between protected and recovery environments; proper DNS and routing configuration; proper Active Directory/LDAP configuration; low packet-loss WAN connectivity. |
| Cloud assumptions | Active enterprise cloud subscriptions/accounts; appropriate cloud IAM permissions; cloud quotas can be increased as required. |
| Hypervisor and source environment assumptions | CBT is enabled where applicable; snapshot operations are functioning normally; source storage latency is within vendor-recommended limits; supported hypervisor versions are deployed. |
| Operational assumptions | Replication scheduling is appropriately staggered for large environments; recovery subnet/IP capacity is pre-planned; DR testing is periodically performed; sufficient recovery compute capacity is available in the target cloud/region. |
Scalability assumptions
The replication and recovery guidance in this document assumes:
- Rolling-window replication protocol v2 is enabled
- Multi-threaded replication is enabled
- Replication nodes are deployed using recommended sizing guidance
- Horizontal scaling is used for large environments
Actual scalability depends on:
- Workload change rates
- CBT fragmentation characteristics
- WAN bandwidth and latency
- Cloud API performance
- Storage throughput characteristics
- Recovery concurrency
Scope of this document
This document focuses specifically on:
- Datamotive component architecture
- Replication engine scalability
- Node sizing guidance
- Replication concurrency
- Recovery concurrency
- Cloud quota planning
- API throttling considerations
- Capacity planning guidance
- Platform-specific operational considerations
Architectural overview
The Datamotive Workload Portability Platform is designed as a distributed, horizontally scalable architecture that separates management, replication and recovery orchestration into independent functional components.
The platform is optimized for enterprise-scale disaster recovery and workload mobility use cases across on-premises and public cloud environments, with a strong focus on:
- Scalability
- Predictable recovery operations
- WAN-efficient replication
- Cloud-native recovery
- Operational simplicity
- Horizontal expansion
The architecture supports both small deployments using a minimal number of nodes and large-scale deployments spanning hundreds of workloads across multiple sites and cloud regions.
High-level architecture
The Datamotive platform consists of the following logical layers.
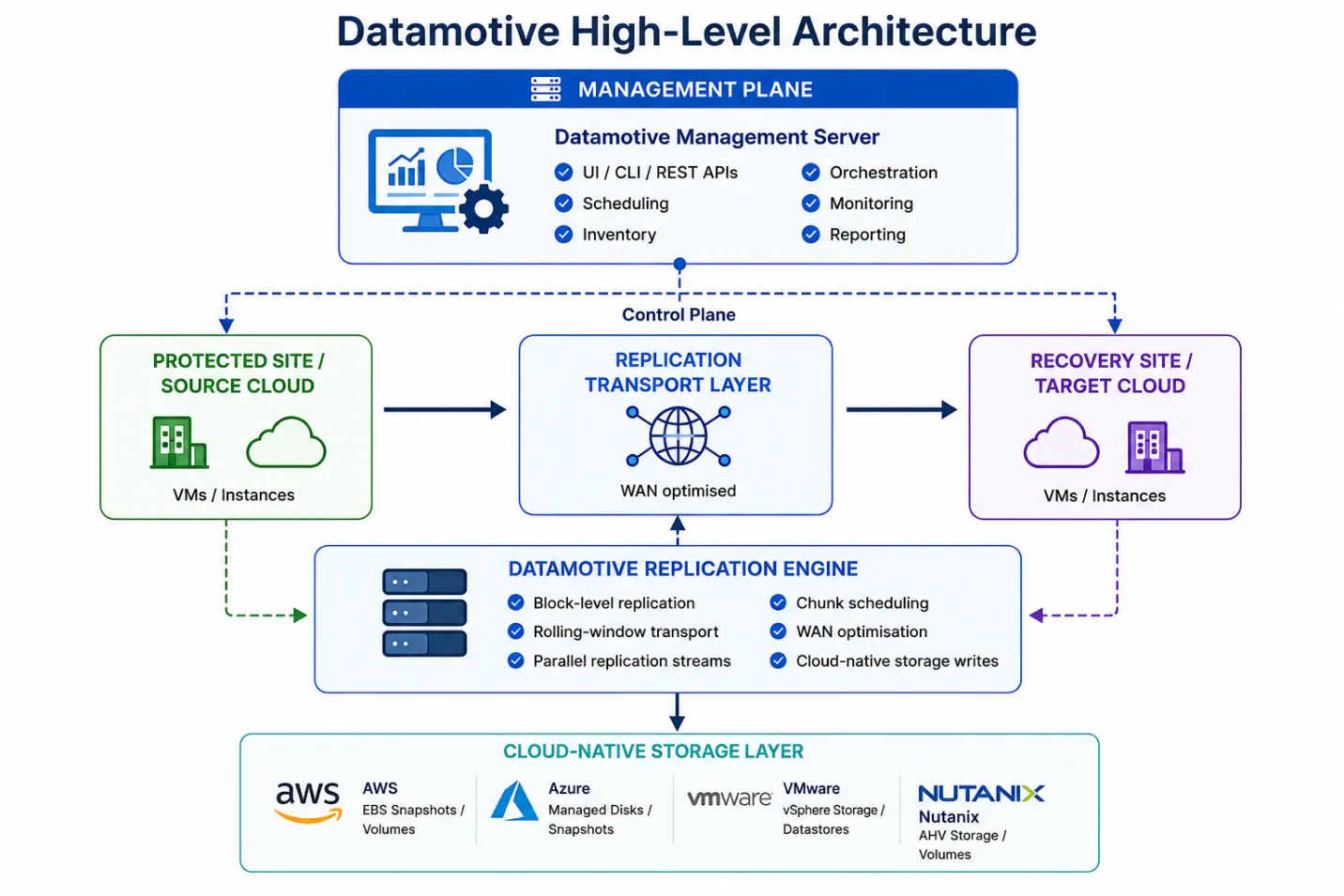
Architectural design principles
The Datamotive platform is designed around several core architectural principles.
Agentless replication
Datamotive performs replication without requiring guest operating system agents inside protected workloads.
Benefits include:
- Simplified deployment
- Reduced operational overhead
- Lower workload impact
- Reduced security footprint
- Simplified lifecycle management
Block-level incremental replication
The platform performs block-level replication using native hypervisor or cloud incremental tracking mechanisms where available.
This approach enables:
- Efficient WAN utilization
- Reduced replication overhead
- Faster replication intervals
- Scalable incremental recovery
Rolling-window replication architecture
The Datamotive replication engine uses adaptive rolling-window transport architecture optimized for WAN transports replication fragmented enterprise workloads while ensuring reliability and data integrity.
Key characteristics include:
- Sliding-window replication
- Parallel chunk streaming
- Descriptor-driven scheduling
- Worker-controlled flow management
- Node-level backpressure handling
- Adaptive concurrency management
This architecture is specifically designed to avoid the inefficiencies associated with traditional stop-and-wait replication models.
Horizontal scalability
The platform is designed to scale horizontally through the addition of Replication Nodes and supporting infrastructure components.
This allows the platform to support:
- Large-scale replication environments
- High parallel recovery operations
- Cross-region DR architectures
- Multi-cloud disaster recovery
The Datamotive Replication and Recovery Nodes can also be scaled vertically to achieve the most optimum deployment model based on specific customer needs.
Cloud-native recovery
Datamotive integrates directly with cloud-native storage and compute APIs.
Recovery workflows use:
- AWS EBS snapshots and volumes
- Azure Managed Disks and snapshots
- VMware vSphere SDKs
- Nutanix Prism & Prism Central SDKs
This approach enables:
- Reduced recovery infrastructure requirements
- Elastic recovery scaling
- Cloud-native recovery orchestration
- Simplified DR operations
Control plane and data plane separation
The Datamotive architecture separates management and orchestration operations from replication data movement operations and target site / DR site recovery operations.
Control plane responsibilities
The control plane is responsible for:
- Scheduling
- Policy management
- Inventory tracking
- Recovery orchestration
- Monitoring
- API management
- Metadata operations
Data plane responsibilities
The data plane is responsible for:
- Block replication
- Chunk streaming
- Flow control
- Cloud storage writes
- Data integrity validation
- Recovery reads
This separation provides:
- Better scalability
- Improved fault isolation
- Simplified horizontal expansion
- Independent scaling of management and replication workloads
Replication workflow overview
The Datamotive replication workflow consists of the following high-level stages.
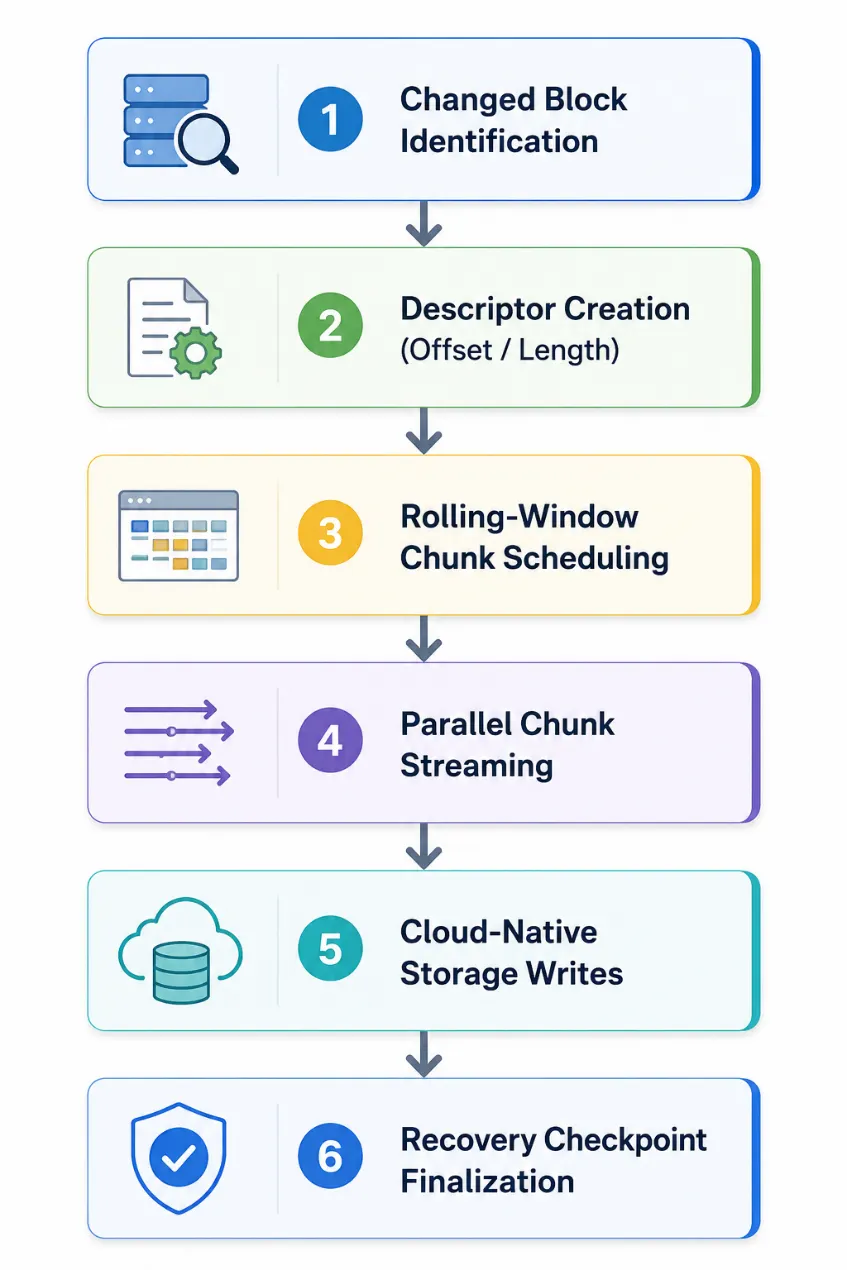
Recovery overview
The recovery architecture is designed for large-scale parallel recovery operations across cloud and on-premises environments.
Recovery workflows include:
- Disk reconstruction
- Snapshot finalization
- System health checks for Windows workloads
- VM instantiation
- Network attachment
- Boot order orchestration
- Recovery validation
The platform supports:
- Full site failover
- Partial failover
- Test failover
- Cross-cloud recovery
- Granular workload recovery
Recovery orchestration is designed to operate in parallel while respecting cloud API limits, quota constraints, and storage concurrency limits.
Scalability model
Datamotive scalability is achieved through a combination of:
- Parallel replication streams
- Sliding-window replication
- Vertical or Horizontal replication-node expansion
- Distributed recovery orchestration
The architecture is designed such that:
- Small environments can operate using minimal infrastructure
- Large environments can scale horizontally using additional Replication Nodes
- Recovery throughput scales independently from management operations
- Replication throughput scales independently from orchestration operations
This model enables predictable scaling across a wide range of enterprise deployment sizes.
Component architecture
The Datamotive Workload Portability Platform is composed of multiple independently deployable infrastructure components designed to provide scalable, secure, and cloud-native disaster recovery, replication, migration, and workload mobility capabilities across on-premises and public cloud environments.
The platform architecture is designed around a clear separation of:
- Management and orchestration operations
- Replication and data movement operations
- Recovery preparation workflows
- Storage optimization services
This modular architecture enables:
- Independent component scaling
- Operational flexibility
- Horizontal expansion
- Fault isolation
- Cloud-native deployment models
- Multi-site and multi-cloud deployments
All Datamotive appliances are based on CIS-hardened Ubuntu Server 22 LTS images and are delivered either as:
- Pre-packaged virtual appliances for hypervisor-based deployments
- Cloud-native machine images for public cloud environments
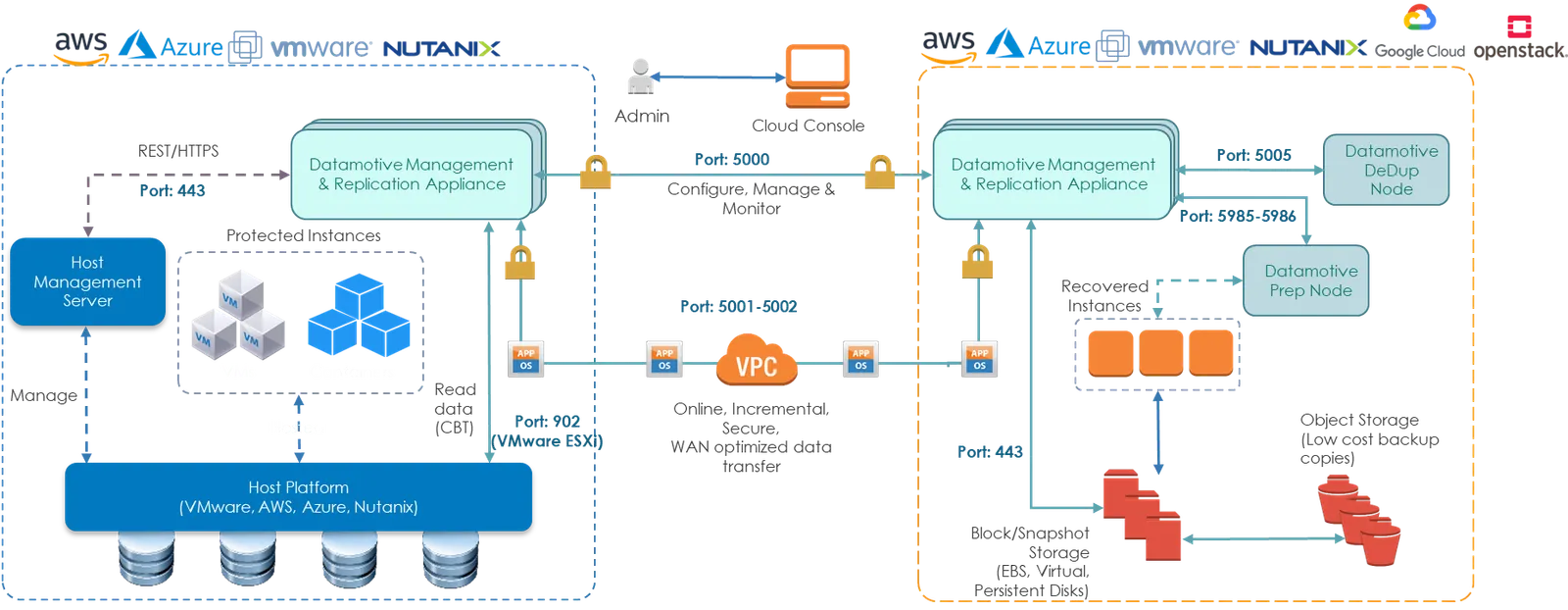
Datamotive Management Server
The Datamotive Management Server is the central orchestration and control-plane component of the platform.
It is responsible for:
- User interface (UI), Command-line interface (CLI), RESTful APIs
- Policy management
- Replication orchestration
- Recovery orchestration
- Scheduling
- Monitoring and alerting
- Reporting
- Inventory and metadata management
- Day-0 through Day-N operational workflows
The Management Server coordinates all platform activities while maintaining operational metadata, workflow state, inventory information, and recovery orchestration logic.
The Management Server must be deployed:
- At the protected site
- At the recovery site
For smaller deployments, the Management Server can additionally function as a Replication Node.
Management Server deployment formats
| Platform | Deployment format |
|---|---|
| VMware | OVA |
| Nutanix | OVA |
| AWS | Cloud-native AMI |
| Azure | Cloud-native VM Image |
Recommended Management Server sizing
| Environment scale | vCPU | Memory | Storage |
|---|---|---|---|
| Very Small | 4vCPU | 8 GB | 120GB SSD |
| Small | 4 vCPU | 16 GB | 200 GB SSD |
| Medium | 8 vCPU | 24 GB | 500 GB SSD |
| Large | 16 vCPU | 32 GB | 1 TB SSD |
| Very Large | 32 vCPU | 64 GB | 2 TB SSD |
Actual sizing depends on:
- Number of protected workloads
- Recovery orchestration concurrency
- Historical data retention requirements
- Reporting requirements
- API activity levels
- Multi-site deployment scale
Datamotive Replication Node
The Datamotive Replication Node is the primary data-plane component responsible for executing replication data operations.
Replication Engines are deployed at both the protected site and the recovery site and are responsible for:
- Block-level replication
- Incremental change processing
- Rolling-window transport management
- Parallel stream handling
- WAN-optimized data transfer
- Descriptor-driven chunk scheduling
- Data integrity validation
- Cloud-native storage writes
- Recovery data reads
- Flow-control management
- Recovery checkpoint finalization
The replication architecture is optimized for:
- Highly fragmented CBT workloads
- Enterprise-scale replication
- Large numbers of parallel workloads
- WAN-constrained environments
- Cross-cloud replication
- High-churn workloads
- Cloud-native storage APIs
The Datamotive platform scales horizontally through the deployment of additional Replication Engines, enabling large-scale parallel replication across thousands of protected workloads.
Replication Engine architecture
The Datamotive replication engine uses a rolling-window replication architecture designed to maximize throughput efficiency across fragmented block-level workloads.
Key architectural characteristics include:
- Sliding-window parallel replication
- Target-side Worker-driven flow control
- Descriptor-based replication scheduling
- Node-level backpressure handling
- Parallel chunk streaming
- Cloud-native storage integration
- Horizontally scalable replication workers
The replication engine is specifically designed to avoid the inefficiencies associated with traditional stop-and-wait replication models.
Platform-specific replication scaling guidance
Replication scalability depends heavily on:
- Source platform behaviour
- Storage performance
- CBT fragmentation characteristics
- WAN bandwidth
- Recovery concurrency
- Cloud-native storage throttling
The following sections provide recommended operational guidance for each supported platform.
VMware replication scaling
For VMware-based environments, replication scale is primarily influenced by:
- VMware CBT fragmentation
- Snapshot performance
- VDDK read concurrency
- Datastore latency
- Snapshot chain depth
- WAN throughput
- Cloud storage write throughput
| Metric | Recommended scale |
|---|---|
| Parallel Replication Jobs | ~60 - 80 protected disks |
| Recommended Parallel VMs | 30-40 VMs |
| Recommended Sustained Throughput | ~1 Gbps WAN replication |
These values represent conservative operational guidance for fragmented enterprise VMware workloads.
Actual scale depends on:
- Disk size distribution
- Average workload churn
- CBT fragmentation characteristics
- Storage subsystem latency
- WAN quality
AWS replication scaling
For AWS-native replication environments, scalability is primarily influenced by:
- EBS API throughput
- Snapshot write concurrency
- EC2 instance network bandwidth
- Regional API throttling
- EBS volume quotas
- Cloud storage concurrency
| Metric | Recommended scale |
|---|---|
| Parallel Replication Jobs | 200-250 protected volumes |
| Recommended Parallel Instances | 100-150 instances |
| Recommended Throughput | ~5 Gbps depending on instance type |
Large-scale AWS environments may additionally require:
- Regional quota increases
- API throttling monitoring
- Multiple Replication Nodes
- Dedicated recovery subnets
- Storage concurrency tuning
Azure replication scaling
For Azure-native replication environments, scalability is primarily influenced by:
- Azure Page Blob API throughput
- ARM API throttling
- Managed disk operation concurrency
- VM network throughput
- Subscription quotas
- Regional vCPU quotas
| Metric | Recommended scale |
|---|---|
| Parallel Replication Jobs | 150 - 300 protected disks |
| Recommended Parallel Instances | 75 - 200 instances |
| Recommended Throughput | Up to 10 - 25 Gbps depending on VM size |
Large Azure environments may additionally require:
- VM-family quota increases
- Managed-disk quota increases
- ARM API throttling optimization
- Horizontal replication scaling
Datamotive Prep Node
The Datamotive Prep Node is a Windows-based recovery preparation appliance deployed within the recovery environment.
The Prep Node is activated only during:
- Windows workload recovery
- Cross-platform migration workflows
- Recovery preparation operations
- Boot remediation workflows
- File System and Registry compatibility checks
Prep Nodes are used primarily during:
- VMware-to-cloud recoveries
- Cross-hypervisor migrations
- Cross-cloud recovery operations
- Windows boot remediation workflows
Recovery scaling guidance
| Metric | Recommended scale |
|---|---|
| Parallel Windows Recoveries per Prep Node | Up to 20 workloads |
Additional Prep Nodes can be deployed horizontally for large-scale recovery events, or can also be scaled vertically with instance types that support larger number of attached disks.
Datamotive DeDup Node
The Datamotive DeDup Node is an optional optimization component deployed within the recovery environment.
The node maintains:
- Chunk checksum indexes
- Previously transferred block metadata
- Deduplicated chunk references
- Chunk reuse mappings
When enabled, the DeDup Node significantly reduces:
- WAN bandwidth consumption
- Cross-cloud transfer costs
- Replication duration
- Repetitive data transfer overhead
The DeDup Node is particularly effective for:
- One-time Migration use cases
- Similar workload datasets
- Large-scale enterprise environments
DeDup operational considerations
Deduplication effectiveness depends on:
- Workload similarity
- Operating system standardization
- Retention duration
- Replication interval frequency
The DeDup Node is optional and can be enabled selectively based on workload characteristics and WAN optimization requirements.
Replication Engine architecture
The Datamotive Replication Engine is designed as a high-performance, distributed, block-level replication framework optimized for enterprise-scale disaster recovery and workload mobility operations.
The replication architecture is specifically engineered to address the challenges associated with:
- Highly fragmented change workloads
- Large-scale parallel replication
- WAN-constrained environments
- Cross-cloud data movement
- Cloud-native storage APIs
- Recovery-time scalability
- High-churn enterprise and VDI environments
At the core of the platform is the Datamotive rolling-window replication architecture, which enables efficient parallel replication while maintaining predictable throughput, scalability, and recovery consistency.
Architectural objectives
The replication engine is designed around the following primary objectives.
Predictable Throughput
Maintain sustained replication throughput across:
- Fragmented workloads
- Large parallel replication sets
- WAN-based deployments
- High-latency cloud environments
Efficient WAN Utilization
Maximize WAN efficiency by:
- Eliminating stop-and-wait replication patterns
- Maintaining continuous data streaming
- Supporting parallel inflight replication windows
- Reducing idle replication gaps
Horizontal scalability
Enable enterprise-scale replication by supporting:
- Large numbers of protected workloads
- Multiple replication engines
- Distributed replication streams
- Parallel recovery operations
Cloud-native integration
Integrate directly with:
- AWS EBS snapshots and volumes
- Azure Managed Disks
- VMware datastores
- Nutanix storage
- GCP Persistent Disks
- Raw Disks
This enables:
- Elastic recovery operations
- Reduced recovery infrastructure
- Cloud-native orchestration
Backpressure-aware replication
The replication engine is designed to adapt dynamically to:
- Storage write latency
- Cloud API throttling
- WAN variability
- Replication-node pressure
- Recovery concurrency
This prevents replication instability and uncontrolled resource amplification.
Evolution of the replication architecture
Traditional replication systems frequently use stop-and-wait transport models.
Typical behaviour:
- Read chunks in batches
- Send chunks
- Wait for acknowledgement
- Send next chunks in batches
While standard, this model introduces significant inefficiencies in modern enterprise environments, particularly when handling:
- Highly fragmented CBT workloads
- WAN latency
- Cloud storage APIs
- Parallel workload replication
These inefficiencies result in:
- WAN underutilization
- Idle pipeline gaps
- Increased replication latency
- Poor scaling characteristics
- Recovery-time bottlenecks
To address these limitations, Datamotive introduced the rolling-window replication architecture.
Rolling-window replication model
The Datamotive replication engine uses a sliding-window architecture designed to maintain continuous parallel replication streams.
Instead of waiting for acknowledgement after every chunk, the replication engine maintains multiple inflight chunks simultaneously.
This enables:
- Continuous WAN utilization
- Reduced RTT sensitivity
- Better cloud write parallelism
- Improved throughput consistency
- Better large-scale replication behaviour
Rolling-window replication flow
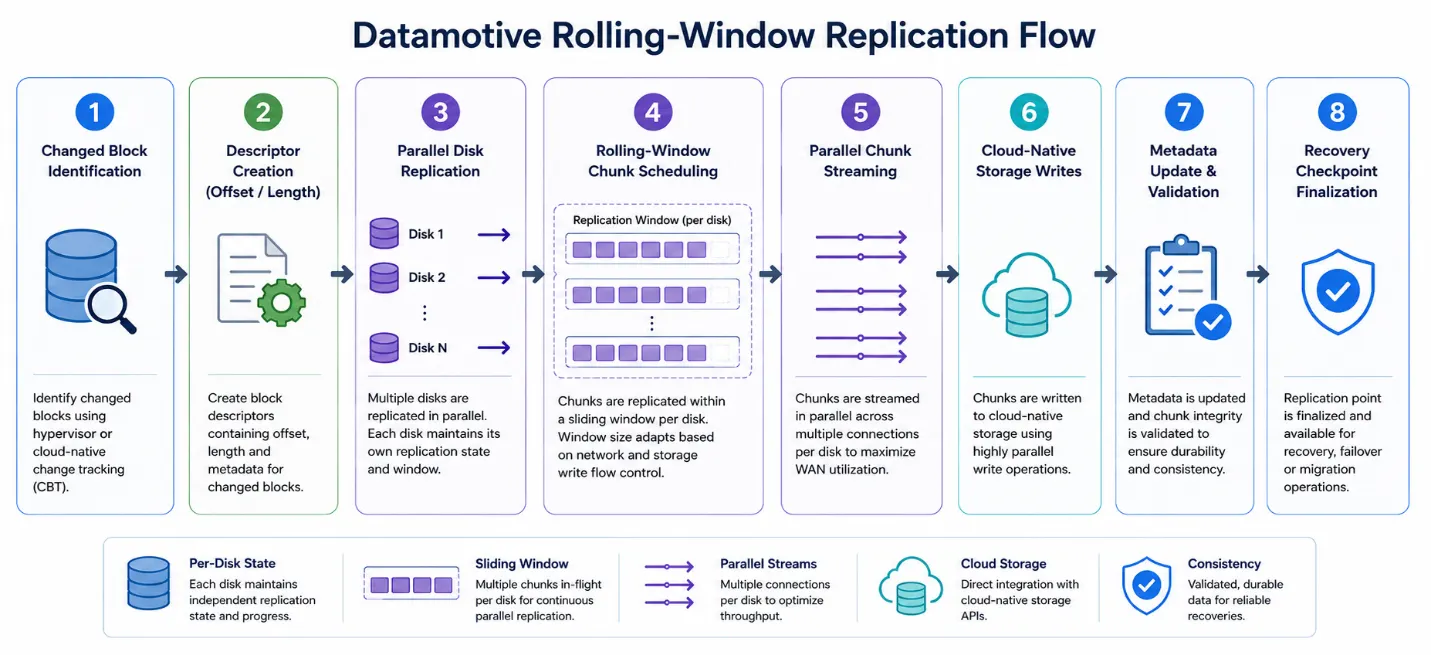
Descriptor-driven replication
The replication engine uses descriptor-driven scheduling instead of sequential block streaming.
Replication descriptors contain:
- Offset
- Length
- Chunk metadata
- Replication state
This model is specifically optimized for fragmented workloads where changed blocks are highly non-sequential.
Benefits include:
- Efficient fragmented-block handling
- Sparse-write optimization
- Reduced unnecessary reads
- Better cloud-write scheduling
- Parallel chunk distribution
Parallel chunk streaming
Replication data is transmitted using parallel chunk streams.
The replication engine maintains multiple inflight chunks simultaneously across:
- Multiple disks
- Multiple workloads
- Multiple replication workers
This architecture avoids:
- Idle WAN periods
- Sequential replication bottlenecks
- Storage-write serialization
- Pipeline starvation
Default operational parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| Chunk Size | size | required | Default chunk size. Default: 1 MB |
| Per-Disk Window | size | required | Default per-disk replication window. Default: 32 MB |
| Intermediate Checkpoint Window | size | required | Default intermediate checkpoint window. Default: 500 MB |
These values represent balanced defaults optimized for:
- WAN efficiency
- Cloud write behaviour
- Memory utilization
- Retransmission overhead
- Fragmented CBT handling
Worker-driven flow control
The Datamotive replication engine uses a worker-controlled pull model.
In this architecture:
- Workers request replication windows
- Clients stream requested chunks
- Workers control inflight concurrency
- Replication pressure is centrally managed
The worker-driven architecture provides:
- Better replication fairness
- Improved backpressure management
- Better cloud-write coordination
- Improved large-scale stability
Node-level backpressure management
The replication engine maintains both:
- Per-disk replication windows
- Node-level inflight replication windows
This architecture prevents:
- Excessive memory amplification
- Cloud-write overload
- Uncontrolled replication bursts
- Storage queue saturation
Backpressure decisions consider:
- Cloud storage latency
- Write queue depth
- Chunk arrival behaviour
- Replication-node pressure
- Error and retry behaviour
Adaptive window scaling
The replication engine dynamically adjusts replication-window sizes based on operational conditions.
Window scaling decisions are influenced by:
- Storage-write pressure
- WAN throughput stability
- Cloud API responsiveness
- Chunk retry rates
- Replication concurrency
Typical per disk operational window levels range between: [16MB | 24MB | 32MB | 48MB | 64MB].
This approach provides:
- Predictable behaviour
- Operational simplicity
- Stable scaling characteristics
- Controlled resource utilization
Recovery checkpoint finalization
Replication operations are finalized into recovery checkpoints after:
- Chunk validation
- Storage-write completion
- Metadata synchronization
- Intermediate validation
- Consistency validation
Recovery checkpoints form the basis for:
- Recovery operations
- Failover workflows
- Test recoveries
- Migration operations
Architectural advantages
The Datamotive rolling-window replication architecture provides several operational advantages over traditional replication models.
| Area | Advantages |
|---|---|
| Improved WAN Efficiency | Reduced idle transmission gaps; better bandwidth utilization; reduced RTT sensitivity. |
| Better Fragmented Workload Handling | Optimized for fragmented CBT; efficient sparse-write handling; parallel chunk scheduling. |
| Improved Cloud Integration | Better cloud-write concurrency; improved API utilization; better recovery scalability. |
| Better Large-Scale Stability | Controlled backpressure handling; adaptive concurrency management; predictable scaling behaviour. |
| Horizontal Scalability | Independent replication-node scaling; distributed replication workloads; better operational flexibility. |
Scalability and performance guidelines
The Datamotive Replication Engine is designed to dynamically adapt replication throughput based on available infrastructure capacity across the complete replication pipeline.
Unlike traditional replication architectures that operate using static or sequential transfer models, the Datamotive rolling-window replication engine continuously balances replication flow across multiple stages of the replication lifecycle.
The effective replication throughput is determined by the combined factors of:
- Source-side read performance
- Changed block processing time
- Network transfer throughput
- Chunk validation time
- Cloud-native storage write throughput
- Recovery checkpoint finalization
The replication engine continuously adapts its inflight replication windows and parallel replication streams based on these operational conditions.
Replication flow control model
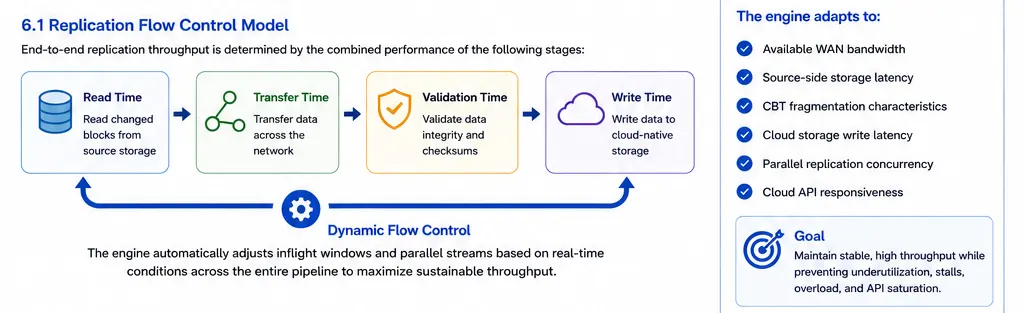
The Datamotive rolling-window replication engine maintains multiple inflight replication windows across parallel disks and workloads simultaneously.
The replication engine automatically adapts to:
- Available WAN bandwidth
- Source-side storage latency
- CBT fragmentation characteristics
- Cloud storage write latency
- Parallel replication concurrency
- Cloud API responsiveness
This allows the replication engine to maintain stable throughput while preventing:
- Network underutilization
- Storage-write overload
- Replication stalls
- Excessive inflight memory growth
- Cloud API saturation
Performance test scenario
The following results represent observed replication performance during internal validation testing.
| Parameter | Value |
|---|---|
| Source Platform | Azure |
| Target Platform | AWS |
| Replication Topology | Azure to AWS |
| Replication Nodes | 1 |
| Protected VMs | 40 |
| Protected Disks | 80 |
| Replication Interval | 20 minutes |
| Average Changed Data per Disk | 700-800 MB |
| WAN Bandwidth | 500 Mbps (Burstable to 700Mbps) |
| Observed Sustained Throughput | ~420 Mbps |
Observations
The replication engine maintained sustained throughput of ~70% of practical WAN limits while handling:
- Parallel disk replication
- Fragmented CBT workloads
- Multiple simultaneous VM replication streams
- Continuous parallel cloud-native storage writes
The observed throughput remained stable across the replication intervals without requiring sequential or serialized replication behaviour.
Recommended Replication Node sizing
| Deployment scale | vCPU | Memory | Network | Recommended workloads | Recommended parallel disks |
|---|---|---|---|---|---|
| Very Small | 4 | 8 GB | Up to 500 Mbps | Up to 30 | 60 - 80 |
| Small | 4 | 16 GB | 1-5 Gbps | 30 - 60 | 80 - 200 |
| Medium | 8 | 32 GB | 10 Gbps | 60 - 150 | 200 - 500 |
| Large | 16 | 64 GB | 10 - 30Gbps | 150 - 300 | 500 - 1000 |
| Very Large | 32 | 128 GB | 50 Gbps+ | 300+ | 1000+ |
The above numbers are recommended assuming ~500MB of change data per disk per replication interval of every 30 mins.
Compute-optimized instance families are recommended for large-scale deployments due to the highly parallel nature of replication operations.
Recommended horizontal scaling guidance
For large enterprise environments, Datamotive recommends horizontal scaling using multiple Replication Nodes.
| Environment size | Recommended Replication Nodes |
|---|---|
| < 50 workloads | 1 |
| 50 - 300 workloads | 2-4 |
| 300 - 1000 workloads | 4-8 |
| >1000 workloads | 8+ |
Horizontal scaling provides:
- Increased aggregate throughput
- Better API distribution
- Improved recovery concurrency
- Reduced node-level contention
- Better operational isolation
Parallel recovery guidance
Recovery concurrency depends primarily on:
- Attached Disks capacity for Prep Node
- Cloud API throttling
- Compute Instance quotas
- Network provisioning concurrency
For scaling recoveries, deploying the Prep Node at a higher configuration enables more than 22 disks to be attached for recovery. It is important to plan for recoveries in batches according to Protection Plans and prepare for Compute Instance quotas on the target cloud.
Cloud quotas and API limits
Cloud-native disaster recovery and replication scalability is heavily influenced by cloud-provider quotas, API throttling behaviour, and storage provisioning limits.
For large-scale replication and recovery operations, cloud APIs frequently become one of the primary operational scaling factors, particularly during:
- Large-scale failovers
- Parallel recovery operations
- Snapshot creation bursts
- Volume provisioning operations
- Cross-region copy operations
- Mass VM power-on orchestration
Datamotive is designed to operate within these limits using:
- Parallel orchestration
- Retry-aware workflows
- Backpressure-aware replication
- Horizontal scaling
- Adaptive concurrency management
However, enterprise-scale deployments should proactively review and increase cloud quotas prior to production onboarding and DR testing.
AWS quotas and API limits
Datamotive primarily interacts with the following AWS services:
| Service | Usage |
|---|---|
| EC2 APIs | VM creation, power operations, orchestration |
| EBS APIs | Snapshot and volume operations |
| EBS Direct APIs | Block-level snapshot writes/reads |
| IAM APIs | Access and orchestration |
| VPC APIs | Network provisioning |
Important AWS scalability limits
| AWS Resource / API | Typical default limit | Notes |
|---|---|---|
| EBS Snapshots per Region | 100,000 | Adjustable |
| Concurrent OpenSnapshot for Write operations | 100 per account | Adjustable (with AWS support request) |
| EBS Volume Attachments per Instance | Instance dependent (typically 28 on Nitro) | Recovery consideration |
| EBS Volume Size | 64 TiB maximum | Per volume |
| Regional EC2 vCPU Quotas | Varies by VM family | Frequently requires increase |
| EBS Direct API Throughput | Account and API limited | Important for parallel recovery |
AWS API throttling behaviour
AWS uses token-bucket throttling for EC2 and EBS APIs.
Important characteristics:
- Throttling occurs per API operation
- Limits vary by API type
- Non-mutating APIs typically have higher limits
- Mutating APIs are throttled more aggressively
Examples of APIs commonly used during Datamotive operations:
| API | Operation Type |
|---|---|
| CreateSnapshot | Storage mutation |
| CreateVolume | Storage mutation |
| AttachVolume | Compute/storage mutation |
| RunInstances | Compute mutation |
| StartInstances | Compute mutation |
| DescribeVolumes | Read operation |
| DescribeSnapshots | Read operation |
AWS returns throttling responses using:
- HTTP 429
RequestLimitExceededThrottlingException
AWS EBS Direct API considerations
For block-level snapshot operations, EBS Direct APIs introduce additional scalability considerations.
Important operational characteristics include:
| Parameter | Typical Behavior |
|---|---|
| Block Size | 512 KB |
| API Throughput Scaling | Based on concurrency |
| Parallel API Calls | Strongly recommended |
| Snapshot Write Throughput | Limited by account/API quotas |
AWS documentation indicates that approximately:
- 1000 PutSnapshotBlock operations/sec can produce roughly 500 MB/s throughput per snapshot workflow under optimal conditions.
AWS quota increase guidance
For enterprise DR environments, Datamotive strongly recommends proactive quota increases for:
| Quota | Recommendation |
|---|---|
| Regional vCPU quotas | Increase before DR onboarding |
| EBS snapshot quotas | Increase for long retention periods |
| EBS volume quotas | Increase for large recoveries |
| Snapshot Write limits | Increase for cross-region DR |
| ENI/IP quotas | Validate during recovery planning |
Quota increases can be requested using:
- AWS Service Quotas
- AWS Enterprise Support
- AWS Support Center
Azure quotas and API limits
Datamotive primarily interacts with:
| Azure Service | Usage |
|---|---|
| Azure Resource Manager (ARM) | Resource orchestration |
| Azure Compute APIs | VM provisioning and operations |
| Azure Managed Disk APIs | Disk and snapshot operations |
| Azure Networking APIs | NIC and network provisioning |
| Azure Subscription Quotas | Regional compute allocation |
Important Azure scalability limits
| Azure Resource / API | Typical default limit | Notes |
|---|---|---|
| Managed Disks per Subscription/Region | 50,000 per disk type | Adjustable |
| Incremental Snapshots per Disk | 500 | Important for retention planning |
| Regional vCPU Quotas | Subscription dependent | Frequently requires increase |
| VM Family Quotas | Region and family specific | Common DR bottleneck |
| ARM API Requests | Subscription and region throttled | Critical for parallel recovery |
| Concurrent Disk Operations | Compute/provider throttled | Recovery consideration |
Azure ARM API throttling
Azure Resource Manager (ARM) applies throttling at multiple levels:
- Subscription
- Region
- Resource provider
- Service principal
- API operation type
Operations commonly impacted during large-scale recoveries include:
| API Category | Examples |
|---|---|
| VM APIs | VM creation, power operations |
| Disk APIs | Managed disk creation |
| Snapshot APIs | Snapshot creation and deletion |
| Network APIs | NIC and IP provisioning |
| Page Blob APIs | Read and write content |
Typical throttling symptoms include:
- HTTP 429 responses
- Retry-After headers
- Delayed provisioning
- Intermittent API failures
Azure quota increase guidance
Azure quotas are frequently the primary limiting factor for large-scale DR operations.
Datamotive recommends proactively increasing:
| Quota | Recommendation |
|---|---|
| Regional vCPU quotas | Mandatory for enterprise DR |
| VM-family quotas | Required for target recovery VM sizes |
| Managed disk quotas | Increase for large environments |
| NIC quotas | Validate during DR planning |
| Public IP quotas | Validate if public recovery required |
Quota increases can be requested using:
- Azure Portal
- Azure Quota APIs
- Microsoft Support
Practical operational considerations
In large-scale recovery environments, practical scalability is often constrained more by API orchestration behaviour than raw infrastructure capacity.
Common operational bottlenecks include:
- API throttling
- Subscription quota exhaustion
- Disk provisioning concurrency
- Snapshot finalization delays
- VM-family quota exhaustion
- Network provisioning limits
These conditions become particularly important during:
- Mass failover events
- Parallel recovery testing
- Regional evacuations
- Large VDI recovery operations
Datamotive operational recommendations
| Area | Recommendation |
|---|---|
| Quotas | Increase quotas before production onboarding |
| DR Testing | Perform periodic scale testing |
| Recovery Design | Use staged recovery orchestration for massive failovers |
| API Handling | Use retry-aware orchestration |
| Scaling | Use multiple Replication Engines for large environments |
| Monitoring | Continuously monitor throttling behaviour |
| Networking | Pre-plan subnet and IP capacity |
Related docs
Was this page helpful?