Overview
Architecture
Easy Hybrid DR architecture: management, replication, recovery, and cloud-native storage layers.
- Product
- Easy Hybrid DR
- Version
- v2.3.1
- Release status
- GA
- Documentation status
- Published
- Last updated
- Updated
- Reading time
- 2 min read
Easy Hybrid DR uses a distributed architecture that separates management, replication, and recovery orchestration into independently scalable layers. This lets small deployments run with minimal infrastructure while large environments expand with additional replication and recovery nodes.
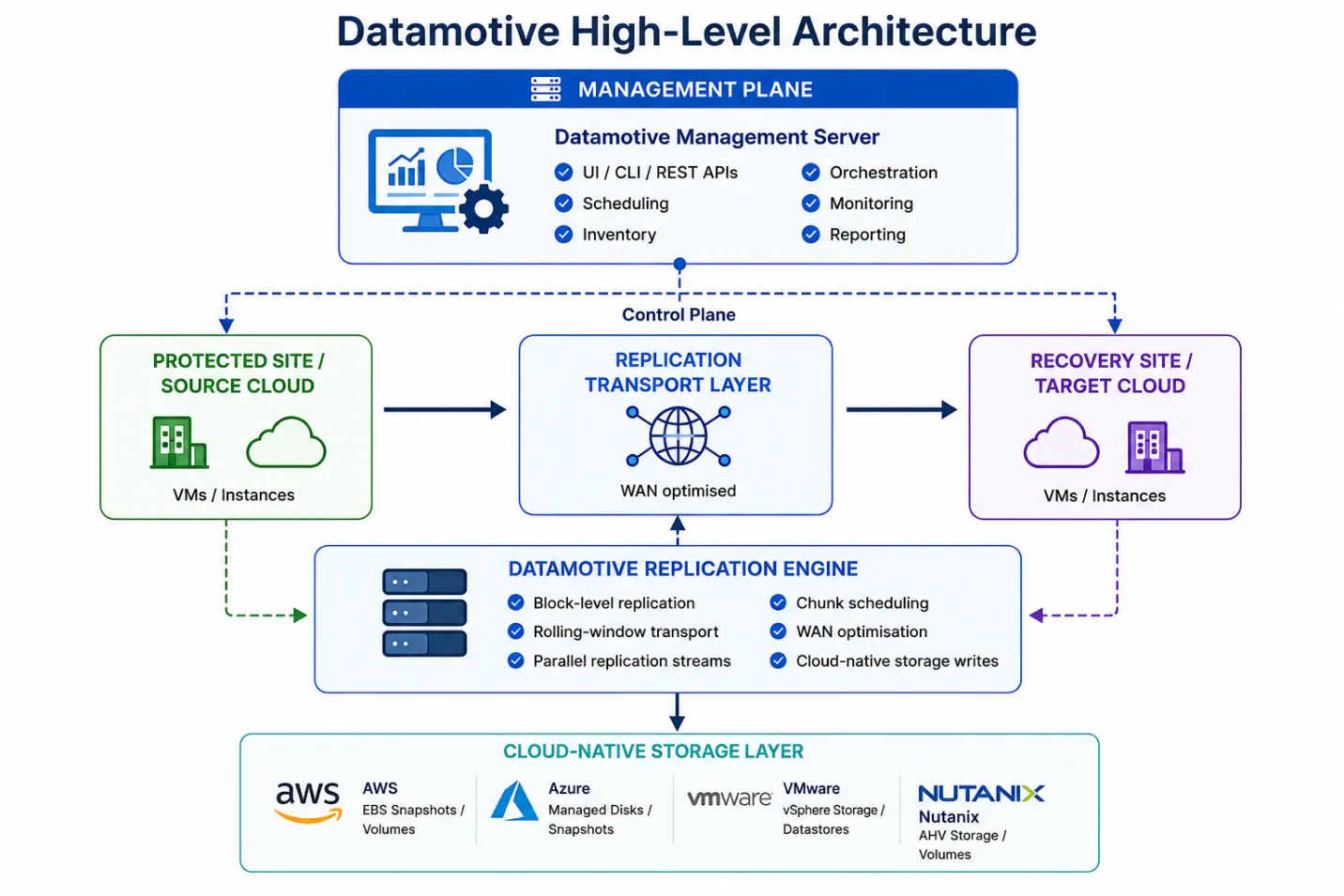
Logical layers
| Layer | Responsibility |
|---|---|
| Management plane | UI, CLI, REST APIs, orchestration, scheduling, monitoring, inventory, reporting, and metadata operations. |
| Protected site or source cloud | Hosts production workloads and provides source snapshots or changed-block APIs. |
| Replication transport layer | Moves changed data using WAN-optimized, rolling-window replication and parallel chunk streams. |
| Replication engine | Performs block-level replication, descriptor scheduling, flow control, validation, and cloud-native storage writes. |
| Recovery site or target cloud | Maintains recovery-ready workloads and cloud resources for failover, drill, or migration operations. |
| Cloud-native storage layer | Stores snapshots, volumes, managed disks, datastores, or AHV storage used for recovery points. |
Design principles
Agentless replication
Easy Hybrid DR performs replication without requiring guest operating system agents inside protected workloads. This simplifies deployment, reduces operational overhead, lowers workload impact, reduces the security footprint, and simplifies lifecycle management.
Block-level incremental replication
The platform uses native hypervisor or cloud incremental tracking mechanisms wherever available. Changed blocks are replicated instead of repeatedly reading entire disks, improving WAN utilization and reducing replication overhead.
Rolling-window transport
The replication engine uses adaptive rolling-window transport for fragmented enterprise workloads. It combines sliding-window replication, descriptor-driven scheduling, parallel chunk streaming, worker-controlled flow management, node-level backpressure, and adaptive concurrency.
Horizontal scalability
The platform scales through additional replication nodes and supporting infrastructure. Replication throughput, recovery throughput, and management operations can be scaled independently.
Cloud-native recovery
Recovery workflows integrate directly with cloud and platform APIs, including AWS EBS snapshots and volumes, Azure Managed Disks and snapshots, VMware vSphere SDKs, and Nutanix Prism APIs.
Control plane and data plane separation
The control plane manages policy, schedules, inventory, recovery orchestration, monitoring, APIs, and metadata. The data plane performs block replication, chunk streaming, cloud storage writes, integrity validation, and recovery reads.
This separation improves fault isolation and lets teams expand management capacity separately from replication capacity.
Replication workflow
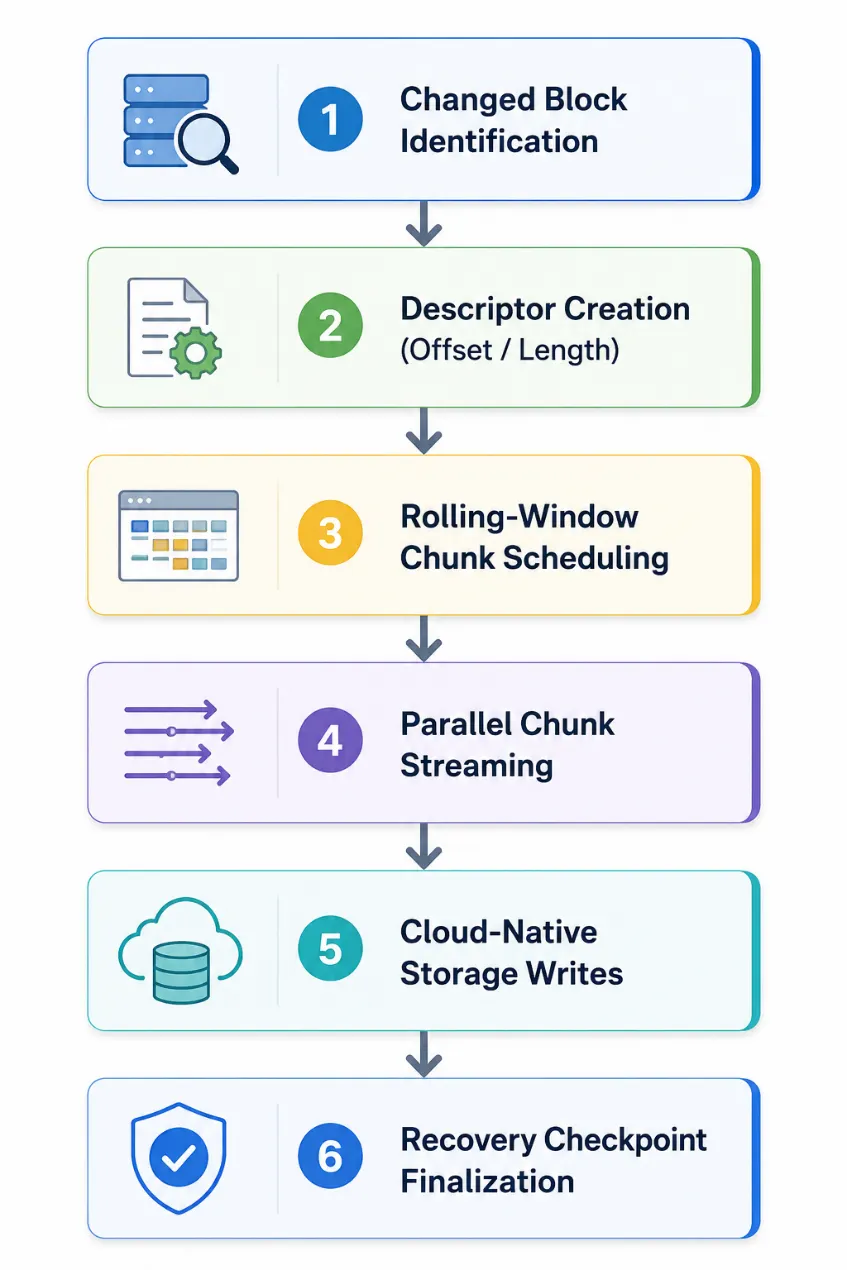
Identify changed blocks
The source adapter uses CBT, changed region tracking, incremental snapshots, or cloud-native APIs to identify data changed since the previous recovery point.
Create descriptors
The engine creates block descriptors with offset, length, metadata, and replication state for each changed range.
Schedule chunks
Rolling-window scheduling keeps multiple chunks in flight per disk while preserving per-disk replication state.
Stream chunks in parallel
Multiple disks, workloads, and workers can transfer data simultaneously to improve WAN utilization.
Write to target storage
Chunks are written to target storage through cloud-native or platform-native APIs.
Finalize the checkpoint
The platform validates data integrity, synchronizes metadata, and exposes the recovery checkpoint for failover, testing, or migration.
Recovery overview
Recovery workflows include disk reconstruction, snapshot finalization, Windows system health checks, VM instantiation, network attachment, boot order orchestration, and recovery validation. Recovery orchestration is parallelized while respecting cloud API limits, quota constraints, and storage concurrency limits.
Related docs
Was this page helpful?